

Recommender Systems
Introduction to Recommender Systems
Recommender systems like Amazon’s “Customers who bought this item also bought” are part of almost every platform on the Web, as well as of many mobile and desktop applications. Hardly any enterprise could afford to ignore personalization techniques and not have a recommender system. Sometimes, recommender systems ‘only’ provide some added value for customers and improve the user experience, but recommender systems are often a central part of a company’s business model. For instance, Amazon’s recommender system increases sales by around 8% [39]. Netflix reports that its recommender system influences users’ choice for 80% of watched movies, and the recommender system contributes more than $1B per year to its business [33]. Other studies of recommender systems also consistently report increases of several percentages in page views, time spent on page and revenue [25].
Figure 1.
Recommendation Approaches
Introduction to Recommender Systems
Recommender systems like Amazon’s “Customers who bought this item also bought” are part of almost every platform on the Web, as well as of many mobile and desktop applications. Hardly any enterprise could afford to ignore personalization techniques and not have a recommender system. Sometimes, recommender systems ‘only’ provide some added value for customers and improve the user experience, but recommender systems are often a central part of a company’s business model. For instance, Amazon’s recommender system increases sales by around 8% [39]. Netflix reports that its recommender system influences users’ choice for 80% of watched movies, and the recommender system contributes more than $1B per year to its business [33]. Other studies of recommender systems also consistently report increases of several percentages in page views, time spent on page and revenue [25].
Figure 1.
There are two main approaches to recommender systems: Content-Based Filtering (CBF) and Collaborative Filtering (CF). In Content-Based Filtering, items with similar content are recommended based on items a user previously interacted with. For instance, if a user reads an article in which the term “Machine Learning” occurs, then other articles that also contain that term would then be recommended. With Collaborative Filtering users are grouped by their taste where taste is usually measured by the similarity of their ratings for some items. For instance, if two users, A and B, both watched the same movies and rated them similarly, the two users would be considered like-minded. Those movies that user A liked but that user B had not yet watched would then be recommended to user B, and vice versa. Sometimes, even very simple recommendation approaches perform well, such as recommending the most popular items (e.g. the most often read/shared/liked news) or items with the highest overall user rating.
Recommender-System Research
From a research perspective, recommender-systems are one of the most diverse areas imaginable. The areas of interest range from hard mathematical/algorithmic problems over user-centric problems (user interfaces, evaluations, privacy) to ethical and political questions (bias, information bubbles). Given this broad range, many disciplines contribute to recommender-systems research including computer science (e.g. information retrieval, natural language processing, graphic and user interface design, machine learning, distributed computing, high performance computing) the social sciences, and many more. Recommender-systems research can also be conducted in almost every domain including e-commerce, movies, music, art, health, food, legal, or finance. This opens the door for interdisciplinary cooperation with exciting challenges and high potential for impactful work.
My Own Recommender-Systems Research
Overview
I have worked in the field of recommender systems for more than a decade, and developed several recommender systems myself including Docear [16], Mr. DLib [4] and Darwin & Goliath. I worked with industry partners and the ADAPT Research Centre on recommender systems and released large-scale datasets to facilitate the research on recommender-systems including Docear [19], RARD [22], and DonorsChoose [29]. I have developed novel recommendation algorithms including a privacy-preserving TF-IDF variant [18], citation proximity and pattern algorithms [31, 32], and a mind-map based user-modelling algorithm [20]. So-called ‘soft’ questions also caught my interest such as: How many recommendations to display [23, 27]? How frequently to give recommendations to users [17]? Are there differences in recommendation effectiveness for different users (e.g. age groups and genders) [21, 36]? How to label recommendations, and are there perceived differences between commercial and non-commercial recommendations even if the recommended items are identical [14]?
Recommender-System Evaluation
‘What constitutes a good recommender system and how to measure it’ might seem like a simple question to answer, but it is actually quite difficult. For many years, the recommender-systems community focused on accuracy. Accuracy, in the broader sense, is easy to quantify: numbers like error rates such as the difference between a user’s actual rating of a movie and the previously predicted rating by the recommender system (the lower the error rate, the better the recommender system); or precision, i.e. the fraction of items in a list of recommendations that was actually bought, viewed, clicked, etc. (the higher the precision, the better the recommender system). Recently, the community’s attention has shifted to other measures that are more meaningful but also more difficult to measure including serendipity, novelty, and diversity. I contributed to this development by critically analyzing the state of the art [15] ; comparing evaluation metrics (click-through rate, user ratings, precision, recall, …) and methods (online evaluations, offline evaluations, user studies) [13] as well as introducing novel evaluation methods [3].
Regardless of the metrics used to measure how “good” a recommender system is (accuracy, precision, user satisfaction…), studies report surprisingly inconsistent results on how effective different recommendation algorithms are. For instance, as shown in Figure 2, one of my experiments shows that five news recommendation-algorithms perform vastly different on six news websites [5]. Almost every algorithm performed best on at least one news website. Consequently, the operator of a new news website would hardly know which of the five algorithms is the best to use, because any one could potentially be it.
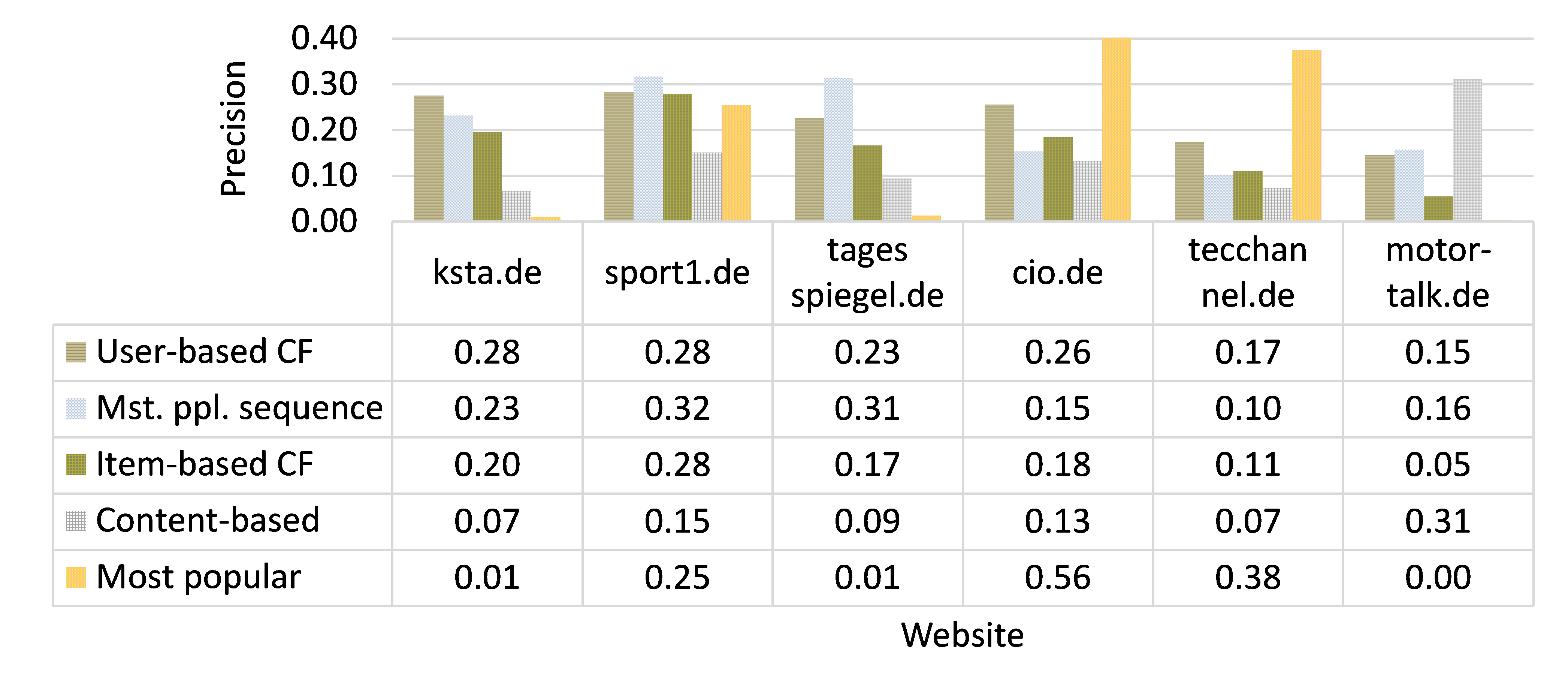 Figure 2.
Figure 2.
Moreover, algorithm performance varies strongly within individual systems, based on the time of the day, users’ gender, the number of displayed recommendations and many more factors. On the website sport1.de, the “Most popular” algorithm performs, overall, second worst with a precision of 0.25 (Figure 1). However, between 4:00 and 18:00 o’clock it performs best with a precision of up to 0.32 (Figure 2). Consequently, an ideal recommender system would use different algorithms at different times of the day. However, manually identifying when to use which algorithm, seems impossible given the vast number of attributes that affect performance [5].
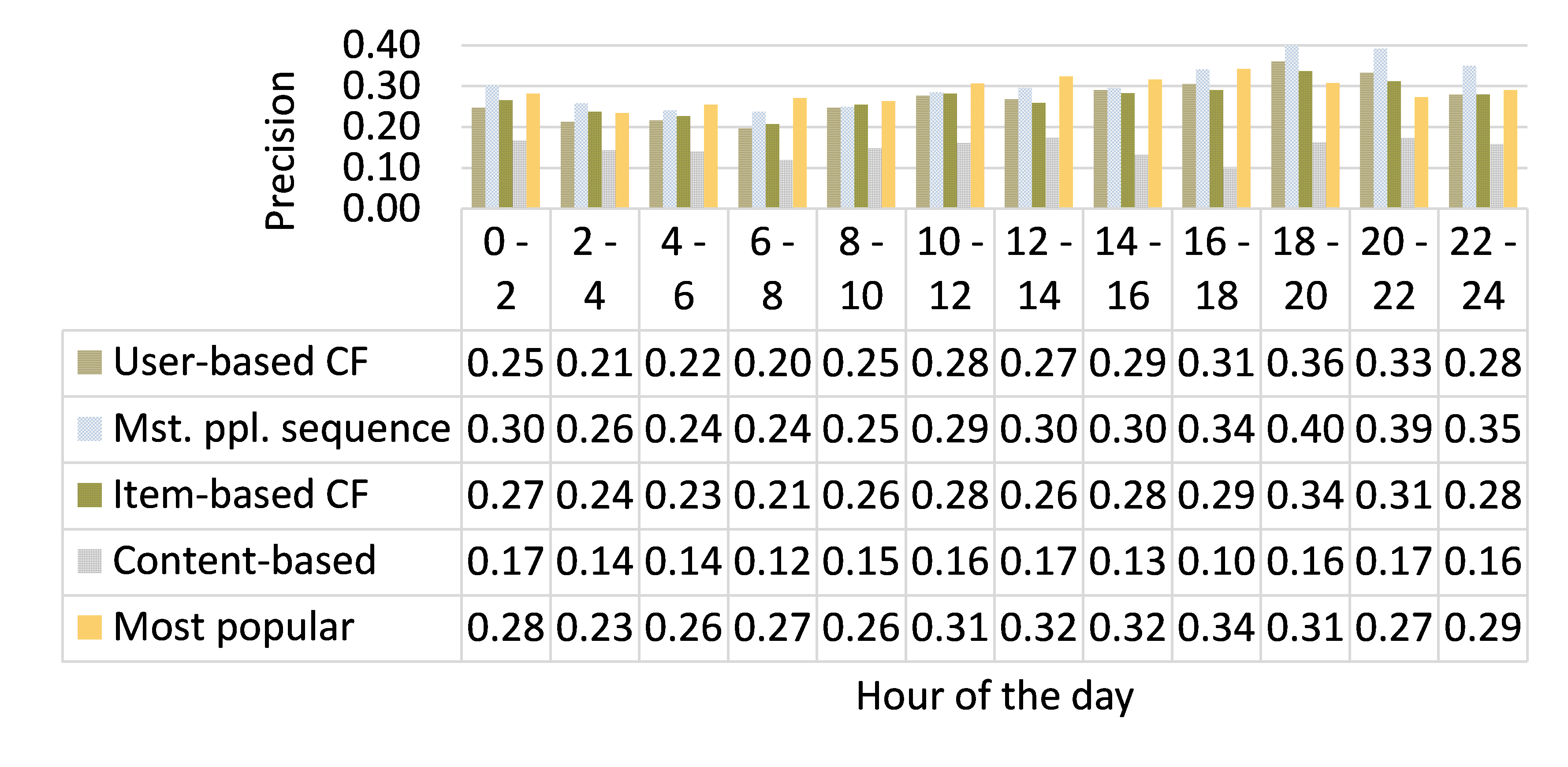 Figure 3.
Figure 3.
This inconsistency in algorithm performance, eventually led to my current research focus: 1. Automating algorithm selection for finding the most effective recommendation algorithm for a given platform (regardless of how ‘effectiveness’ is measured); 2. Facilitating the use of recommender systems through recommender systems as-a-service.
Automated Algorithm-Selection in Recommender Systems
Algorithm selection for recommender-systems can be performed at two levels, macro level and micro level
Macro Level
We define macro algorithm selection as the process of identifying the most effective algorithm for an entire platform, e.g. a news website (cf. Figure 2 ) [2]. This type of algorithm selection and configuration is a well explored area that evolved around 1975 [38]. Automated algorithm selection still receives a lot of attention through the machine learning community with dedicated workshops/competitions [37, 41, 42] and books [34]. In recent years, all major AI and machine learning companies explored this area, including DataRobot, h2o.ai and Google.
One common approach to algorithm selection is based on meta-learning. In this approach, a machine learning model is build based on performance evaluations of many datasets. For an unseen dataset, the model can then predict which algorithm to use. The challenge in this approach lies in properly describing datasets through meta features and having a large amount of data for learning. Our goal is to bring the advances that the machine learning community made in meta-learning to recommender-systems. This will dramatically reduce costs and time for testing algorithms.
Micro Level / Per-Instance
We define micro algorithm selection as the process of identifying the best algorithm for a given problem instance, e.g. a single request for recommendations for a particular user at a particular time in a particular context (cf. Figure 3 ) [2]. Such per-instance based algorithm selection has worked very well in the Boolean Satisfiability (SAT) community, among others. The SAT community deals with algorithms (“solvers”) to determine whether a Boolean formula (with potentially millions of values) is solvable. The community itself usually does not apply machine learning to solve their problems. However, they apply machine learning as a meta-learning technique to identify which solver is best for a given Boolean formula. The SAT community has organized the SAT Competition for the last 17 years. For many years, meta-learners outperform single solvers. For instance, the per-instance meta-learner SATZilla solved 88.5% of the problems while the best single solver solved only 79.2% [1]. This is an improvement of 11.7%, which we aim to bring to the recommender-systems community.
We conducted initial experiments for meta-learned micro algorithm selection in the field of recommender systems. In one experiment we achieved a 2.6% increase in F1 (0.909 vs. 0.886) over the best single parser [40]. In another experiment, we explored the MovieLens dataset and showed that a per-instance meta-learner potentially could improve recommendation performance by 25.5% if the learner was capable of always selecting the best single algorithm [28]. We also organized the AMIR workshop to raise awareness of the recommender-systems and information-retrieval community with respect to the algorithm selection problem [12].
Recommendations-as-a-Service (RaaS)
To facilitate the use of my research in practice, my team and I developed Darwin & Goliath. Darwin & Goliath is a recommender-system as-a-service that allows small and medium-sized enterprises (SME) to integrate a recommender system in their website, app or desktop application within minutes. Darwin & Goliath applies our Micro Recommender-System technique, i.e. it identifies the best algorithm for each platform and user for a given time and context. The workflow of Darwin & Goliath is simple (Figure 4): An SME integrates the D&G client into its product; D&G automatically indexes the SME’s inventory (e.g. news, patents, job offers, e-commerce products); whenever a user visits the SME’s website the D&G client requests and displays the recommendations that are calculated in-real time on Darwin & Goliath’s server.

Figure 4.
The algorithm selection in Darwin & Goliath is done via meta-learning and automated A/B testing to learn in which situation which algorithm performs best. To date, Darwin & Goliath, and its predecessor Mr. DLib, have delivered more than 100 million recommendations and the two services were key to many of our research studies [4, 6–11, 22–24, 26–28, 30, 35].
References
[1] Balint, A., Belov, A., Järvisalo, M. and Sinz, C. 2015. Overview and analysis of the SAT Challenge 2012 solver competition. Artificial Intelligence. 223, (2015), 120–155.
[2] Beel, J. 2017. A Macro/Micro Recommender System for Recommendation Algorithms [Proposal]. ResearchGate https://www.researchgate.net/publication/322138236_A_MacroMicro_Recommender_System_for_Recommendation_Algorithms_Proposal. (2017).
[3] Beel, J. 2017. It’s Time to Consider “Time” when Evaluating Recommender-System Algorithms [Proposal]. arXiv:1708.08447. (2017).
[4] Beel, J., Aizawa, A., Breitinger, C. and Gipp, B. 2017. Mr. DLib: Recommendations-as-a-service (RaaS) for Academia. Proceedings of the 17th ACM/IEEE Joint Conference on Digital Libraries (Toronto, Ontario, Canada, 2017), 313–314.
[5] Beel, J., Breitinger, C., Langer, S., Lommatzsch, A. and Gipp, B. 2016. Towards Reproducibility in Recommender-Systems Research. User Modeling and User-Adapted Interaction (UMUAI). 26, 1 (2016), 69–101.
[6] Beel, J., Carevic, Z., Schaible, J. and Neusch, G. 2017. RARD: The Related-Article Recommendation Dataset. D-Lib Magazine. 23, 7/8 (Jul. 2017), 1–14.
[7] Beel, J., Collins, A. and Aizawa, A. 2018. The Architecture of Mr. DLib’s Scientific Recommender-System API. Proceedings of the 26th Irish Conference on Artificial Intelligence and Cognitive Science (AICS) (2018), 78–89.
[8] Beel, J., Collins, A., Kopp, O., Dietz, L.W. and Knoth, P. 2019. Online Evaluations for Everyone: Mr. DLib’s Living Lab for Scholarly Recommendations. Proceedings of the 41st European Conference on Information Retrieval (ECIR) (2019), 213–219.
[9] Beel, J. and Dinesh, S. 2017. Real-World Recommender Systems for Academia: The Gain and Pain in Developing, Operating, and Researching them [Long Version]. arxiv pre-print. https://arxiv.org/abs/1704.00156 (2017).
[10] Beel, J., Dinesh, S., Mayr, P., Carevic, Z. and Raghvendra, J. 2017. Stereotype and Most-Popular Recommendations in the Digital Library Sowiport. Proceedings of the 15th International Symposium of Information Science (ISI) (2017), 96–108.
[11] Beel, J., Dinesh, S., Mayr, P., Carevic, Z. and Raghvendra, J. 2017. Stereotype and Most-Popular Recommendations in the Digital Library Sowiport [Dataset]. Harvard Dataverse.
[12] Beel, J. and Kotthoff, L. 2019. Proposal for the 1st Interdisciplinary Workshop on Algorithm Selection and Meta-Learning in Information Retrieval (AMIR). Proceedings of the 41st European Conference on Information Retrieval (ECIR) (2019), 383–388.
[13] Beel, J. and Langer, S. 2015. A Comparison of Offline Evaluations, Online Evaluations, and User Studies in the Context of Research-Paper Recommender Systems. Proceedings of the 19th International Conference on Theory and Practice of Digital Libraries (TPDL) (2015), 153–168.
[14] Beel, J., Langer, S. and Genzmehr, M. 2013. Sponsored vs. Organic (Research Paper) Recommendations and the Impact of Labeling. Proceedings of the 17th International Conference on Theory and Practice of Digital Libraries (TPDL 2013) (Valletta, Malta, Sep. 2013), 395–399.
[15] Beel, J., Langer, S., Genzmehr, M., Gipp, B., Breitinger, C. and Nürnberger, A. 2013. Research Paper Recommender System Evaluation: A Quantitative Literature Survey. Proceedings of the Workshop on Reproducibility and Replication in Recommender Systems Evaluation (RepSys) at the ACM Recommender System Conference (RecSys) (2013), 15–22.
[16] Beel, J., Langer, S., Genzmehr, M. and Nuernberger, A. 2013. Introducing Docear’s Research Paper Recommender System. Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL’13) (2013), 459–460.
[17] Beel, J., Langer, S., Genzmehr, M. and Nürnberger, A. 2013. Persistence in Recommender Systems: Giving the Same Recommendations to the Same Users Multiple Times. Proceedings of the 17th International Conference on Theory and Practice of Digital Libraries (TPDL 2013) (Valletta, Malta, Sep. 2013), 390–394.
[18] Beel, J., Langer, S. and Gipp, B. 2017. TF-IDuF: A Novel Term-Weighting Scheme for User Modeling based on Users’ Personal Document Collections. Proceedings of the 12th iConference (2017).
[19] Beel, J., Langer, S., Gipp, B. and Nuernberger, A. 2014. The Architecture and Datasets of Docear’s Research Paper Recommender System. D-Lib Magazine. 20, 11/12 (2014).
[20] Beel, J., Langer, S., Kapitsaki, G.M., Breitinger, C. and Gipp, B. 2015. Exploring the Potential of User Modeling based on Mind Maps. Proceedings of the 23rd Conference on User Modelling, Adaptation and Personalization (UMAP) (2015), 3–17.
[21] Beel, J., Langer, S., Nuenberger, A. and Genzmehr, M. 2013. The Impact of Demographics (Age and Gender) and Other User Characteristics on Evaluating Recommender Systems. Proceedings of the 17th International Conference on Theory and Practice of Digital Libraries (TPDL 2013) (Valletta, Malta, Sep. 2013), 400–404.
[22] Beel, J., Smyth, B. and Collins, A. 2019. RARD II: The 94 Million Related-Article Recommendation Dataset. Proceedings of the 1st Interdisciplinary Workshop on Algorithm Selection and Meta-Learning in Information Retrieval (AMIR) (2019).
[23] Beierle, F., Aizawa, A. and Beel, J. 2019. Choice Overload in Research-Paper Recommender Systems. International Journal of Digital Libraries. (2019).
[24] Beierle, F., Aizawa, A. and Beel, J. 2017. Exploring Choice Overload in Related-Article Recommendations in Digital Libraries. 5th International Workshop on Bibliometric-enhanced Information Retrieval (BIR) at the 39th European Conference on Information Retrieval (ECIR) (2017), 51–61.
[25] Belluf, T., Xavier, L. and Giglio, R. 2012. Case Study on the Business Value Impact of Personalized Recommendations on a Large Online Retailer. Proceedings of the Sixth ACM Conference on Recommender Systems (Dublin, Ireland, 2012), 277–280.
[26] Collins, A. and Beel, J. 2019. Keyphrases vs. Document Embeddings vs. Terms for Recommender Systems: An Online Evaluation. Proceedings of the ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL) (2019).
[27] Collins, A., Tkaczyk, D., Aizawa, A. and Beel, J. 2018. Position Bias in Recommender Systems for Digital Libraries. Proceedings of the iConference (2018), 335–344.
[28] Collins, A., Tkaczyk, D. and Beel, J. 2018. A Novel Approach to Recommendation Algorithm Selection using Meta-Learning. Proceedings of the 26th Irish Conference on Artificial Intelligence and Cognitive Science (AICS) (2018), 210–219.
[29] Edenhofer, G., Collins, A., Aizawa, A. and Beel, J. 2019. Augmenting the DonorsChoose.org Corpus for Meta-Learning. Proceedings of The 1st Interdisciplinary Workshop on Algorithm Selection and Meta-Learning in Information Retrieval (AMIR) (2019).
[30] Feyer, S., Siebert, S., Gipp, B., Aizawa, A. and Beel, J. 2017. Integration of the Scientific Recommender System Mr. DLib into the Reference Manager JabRef. Proceedings of the 39th European Conference on Information Retrieval (ECIR) (2017), 770–774.
[31] Gipp, B. and Beel, J. 2010. Citation Based Plagiarism Detection - a New Approach to Identify Plagiarized Work Language Independently. Proceedings of the 21st ACM Conference on Hypertext and Hypermedia (Toronto, Ontario, Canada, 2010), 273–274.
[32] Gipp, B. and Beel, J. 2009. Citation Proximity Analysis (CPA) - A new approach for identifying related work based on Co-Citation Analysis. Proceedings of the 12th International Conference on Scientometrics and Informetrics (ISSI’09) (Rio de Janeiro (Brazil), 2009), 571–575.
[33] Gomez-Uribe, C.A. and Hunt, N. 2016. The netflix recommender system: Algorithms, business value, and innovation. ACM Transactions on Management Information Systems (TMIS). 6, 4 (2016), 13.
[34] Hutter, F., Kotthoff, L. and Vanschoren, J. 2019. Automatic machine learning: methods, systems, challenges. Challenges in Machine Learning. (2019).
[35] Langer, S. and Beel, J. 2017. Apache Lucene as Content-Based-Filtering Recommender System: 3 Lessons Learned. 5th International Workshop on Bibliometric-enhanced Information Retrieval (BIR) at the 39th European Conference on Information Retrieval (ECIR) (2017), 85–92.
[36] Langer, S. and Beel, J. 2014. The Comparability of Recommender System Evaluations and Characteristics of Docear’s Users. Proceedings of the Workshop on Recommender Systems Evaluation: Dimensions and Design (REDD) at the 2014 ACM Conference Series on Recommender Systems (RecSys) (2014), 1–6.
[37] Lindauer, M., Rijn, J.N. van and Kotthoff, L. 2018. The Algorithm Selection Competition Series 2015-17. arXiv preprint arXiv:1805.01214. (2018).
[38] Rice, J.R. 1975. The algorithm selection problem. (1975).
[39] Sharma, A., Hofman, J.M. and Watts, D.J. 2015. Estimating the Causal Impact of Recommendation Systems from Observational Data. Proceedings of the Sixteenth ACM Conference on Economics and Computation (Portland, Oregon, USA, 2015), 453–470.
[40] Tkaczyk, D., Sheridan, P. and Beel, J. 2018. ParsRec: A Meta-Learning Recommender System for Bibliographic Reference Parsing Tools. Proceedings of the 12th ACM Conference on Recommender Systems (RecSys) (2018).
[41] Tu, W.-W. 2018. The 3rd AutoML Challenge: AutoML for Lifelong Machine Learning. NIPS 2018 Challenge (2018).
[42] Vanschoren, J., Brazdil, P., Giraud-Carrier, C. and Kotthoff, L. 2015. Meta-Learning and Algorithm Selection Workshop at ECMLPKDD. CEUR Workshop Proceedings (2015).
Joeran Beel
Dr Joeran Beel is an Ussher Assistant Professor in the Artificial Intelligence Discipline at the School of Computer Science & Statistics at Trinity College Dublin.
Joeran is also a Visiting Professor at the National Institute of Informatics in Tokyo, and he is also affiliated with the ADAPT Research Centre.
In his research, Joeran focuses on automated machine learning (AutoML), information retrieval (IR), and natural language processing (NLP) in applications such as recommender systems, algorithm selection, and document engineering. Joeran has published more than 70 peer-reviewed papers and acquired more than €1 million in funding.